
This article originally appeared on blog.zakjost.com. If you have questions, you can come ask them to me or Neural DSP researcher, Lauri Juvela, here. A video on this topic + an interview with Lauri can be found here.
Introduction
If you play electric guitar, you probably know that “tube amps” have been the gold standard since the beginning. Originally, amplifiers were just about making the guitar louder, but it's become more than that–it's about manipulating the character of the audio to make it sound more pleasing or achieve some artistic effect. What makes vacuum tubes so attractive is the peculiar non-linearities they introduce to the incoming signal as a byproduct of their interactions with the rest of the circuit when they're pushed to the limits of their operating ranges. Or “distortion” for short. If you push a sine wave of 1 kHz through a tube amp at low levels, it will more or less faithfully reproduce the sine wave but at a higher amplitude. But if you increase the input level of that sine wave such that the amp doesn't have enough power to increase its amplitude, it will asymmetrically round off the peaks, which will in turn add new frequency components to the output at the harmonics (e.g. 2 kHz, 3 kHz, 4 kHz…etc), and its this “fingerprint” of new harmonic content that people like, as some harmonics sound more pleasing than others.
But tube amps have drawbacks in almost all other facets: They're often expensive, big and heavy, rely on tech from the WWII era, need ongoing maintenance, operate at lethal voltage/current if you ever need to open one up…etc. Additionally, they're not very versatile in the types of sounds you can get, as the sonic character of an amp is mostly determined by its circuit design. For these reasons, other technologies have been used to try to mimic the tube sound, but without all the hassles.
There is a lot of history here, but this post is going to focus on the recent work of leveraging Machine Learning to directly learn the audio processing characteristics of circuits. This stands in a modern context where digital modeling amplifiers like the Kemper, which rely on traditional Digital Signal Processing (DSP) techniques rather than Machine Learning, have seen mass adoption in the last several years. Here we will discuss what it means to digitally model an amplifier and how Machine Learning is beginning to make an impact. We'll start by discussing the basics of the problem from a Control Theory perspective and how DSP has approached the solution. We'll then present some work on how people are using Machine Learning to solve the problem as well as point to some open source projects so you can build your own ML-powered guitar circuit models.

Traditional Methods
Control Theory basics
Control Theory is about understanding how a system responds to input to generate output and e.g., how to use feedback to better control the system. This is a nice formalism for studying electronic circuits. The “transfer function” is the function that specifies how inputs are transformed to outputs. If we can learn the transfer function of an amplifier, then that function is effectively a substitute for the amp. The process of using real-world data from a system to fit the parameters of a mathematical model of that system is called “system identification” in this literature.
There are different branches of Control Theory to handle different types of systems. Linear Time-Invariant (LTI) systems are ones where the transfer function is linear and does not depend on time, and these are particularly simple to handle. For example, LTI systems have the property that the output is simply the result of a convolution operation on the input with the “impulse response” function, which is relatively easy to obtain from data.
While many audio-related circuits like an EQ section of an amplifier can be appropriately modeled as an LTI system, tube distortion is inherently non-linear because you get more than just the sum of its parts (harmonics in the output that didn't exist in the input). The result is that impulse responses are no longer sufficient for characterizing the system. This class of problems is much more difficult to mathematically model and there are a number of specialized techniques that have been developed that make various assumptions that are appropriate for a narrow set of problems.
In addition to being non-linear, tube distortion is also a dynamic system because the output for a given input will depend on the state of the system, which depends on the history of inputs and therefore varies with time. For example, capacitors charge and discharge at rates that depend on their component properties, and the amp will behave differently depending on how much charge this capacitor currently has stored, which in turn depends on previous inputs.
[Note: There's another class of system, which won't be discussed further here, that is “time-varying”, meaning there's a time-dependent component that's not derived from the previous inputs or system state (e.g., the rate of an oscillator from a chorus or phaser pedal). This is distinct from a “dynamic system”, which only means the hidden state can depend on the history of inputs.]
Traditional Solutions
One of the approaches to solving this “non-linear dynamical system identification” problem is to model the amplifier in blocks 1. For example, the “Wiener-Hammerstein model” has three blocks connected in series:
- A dynamic linear block
- A static non-linear block
- Another dynamic linear block
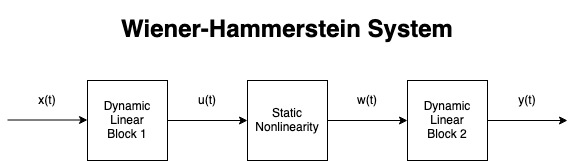
Overall, this system is non-linear and dynamic as we need. By constraining its structure to these serially connected blocks we can separately solve for the parameters of each component at the cost of limiting the types of models we can obtain. For example, it's not clear how well this structure can model the dynamic non-linearities of tubes since all of the dynamic part is captured within the linear blocks and the non-linearity part is merely a static function, like an activation function in a neural network.
There is a spectrum of these types of solutions. A “blackbox” model would treat the real amp design as an unknown and merely attempt to map inputs to outputs. A “whitebox” model would first do some circuit analysis of the amp and try to intelligently segment the circuit so that different functional blocks, like a gain stage, would have dedicated modeling. Once the model structure is set, the process of obtaining a model like this consists of capturing both input and output data of a real amplifier and estimating the parameters of these blocks.
There are other limitations of these methods in addition to the potential performance impact of the constrained solution space of the block models. Notably, the system identification process of fitting parameters based on real amplifier data will do so at a single setting on the amp, but the real amp has multiple knobs you can twist to change the circuit parameters and alter the sound. For example, the gain knob will control the amount of non-linear tube distortion. A different knob setting essentially requires a separate model, and the number of possible amp settings scales exponentially with the number of knobs, which is often more than 5.
I'm not aware of all the ways that real-world systems like the Kemper solve for this, but it's clear that at least some of these problems are avoided by generically modeling things like EQ settings and copy/pasting that to all different amp models, rather than actually modeling how the knob of an amplifier interacts with the rest of the amp. In other words, they capture a single amp setting and apply standard DSP pre- and post-processing to approximate what the knobs would do.
ML for blackbox modeling
Using end-to-end Machine Learning in a blackbox setting affords new possibilities. First, there's no need to restrict the solution space by the explicit construction of limited blocks–it's just learning a function that directly maps inputs to outputs. Second, the values of the knobs can be just another input to the model and it's conceivable that a single model could be learned that meaningfully captured the interaction between the knob values and the sound of the real amp.
Let's pause to think about audio data in general. Humans can typically hear frequencies between about 20 Hz and 20 kHz, which spans 3 orders of magnitude. While you might need 48k points per second to accurately describe the highest frequencies, this is clearly way too much to describe the lower frequencies. Conversely, while you might need 10 ms of audio to capture a complete cycle of the lowest frequencies, this is clearly much more than required to describe higher frequencies. But the very thing that defines “the tone” of an amplifier is in how it responds to different frequencies and amplitudes, so we need to be able to represent and model this full spectrum. The first challenge is in figuring out how we can model relationships that operate at vastly different time-scales. (Translating this challenge to the visual domain, that would be like needing to model object details from meters all the way down to millimeters.)
Another challenge is around model inference speed. For a guitar player to be able to use the model in real-time, it needs to process the audio with around single-digit millisecond latency. This becomes a significant challenge when we have a throughput requirement of 48k samples per second and also need to somehow represent a sliding window of historical data since the amp is a dynamic system.
Model Architectures
One of the model designs that's popular in the literature for solving these problems is WaveNet 2, which was originally developed at DeepMind to generate high quality audio of speech, like for the voices of Alexa or Siri. The key innovation in the WaveNet architecture is that the input audio is represented hierarchically, so that each layer uses a higher level summary of the audio. This allows deeper layers to see increasingly further back in time and ignore fine structure. These are called “dilated convolutions” and are implemented by having each layer skip 2 times as many inputs as the previous layer, resulting in a receptive field that increases exponentially with the number of layers.
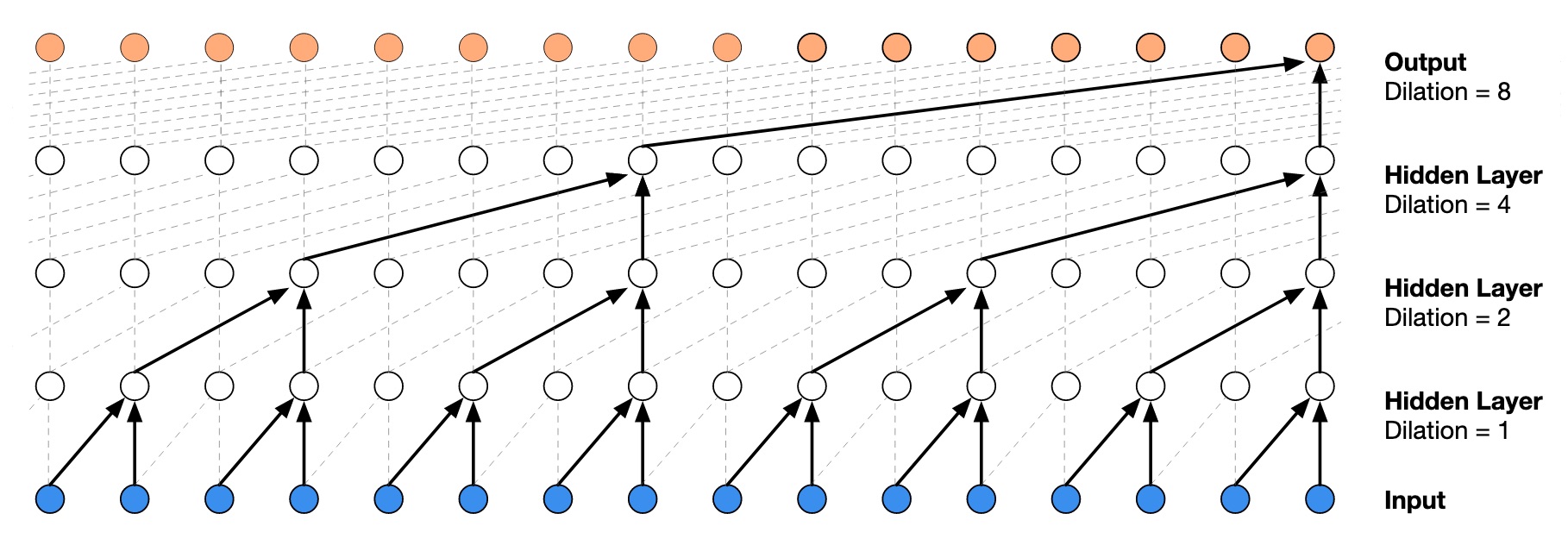
However, the processing required for these models is expensive and real-time performance is difficult to achieve. In reality, this constrains the size of models that can be used both in the depth (which controls receptive field) and number of convolutional channels 3 4. These parameters are strongly correlated with final quality and so there exists a natural trade-off between quality and speed.
Other papers in this space 4 use a Recurrent Neural Net architecture like an LSTM to help combat some of these engineering challenges. This has the obvious advantage that there is a memory state that represents the past time steps so that a smaller chunk of audio can be used during inference, which eliminates the need to add more layers to increase the receptive field. These models did not perform quite as well in high gain settings when comparing loss values, but human listening tests scored them comparably.
Overall it seems that there are multiple architectures that can solve this problem and it really comes down to finding those that can model it efficiently so that high quality and real-time performance can be achieved simultaneously with the given compute budget. This will perhaps become less of an issue as compute continues to scale.
Results
If you'd like to hear some systematic results that compare these approaches, there's a demo page for the LSTM paper 4. Other than that, NeuralDSP is the leader in this space and have a number of incredible sounding demos. Here is their release video of the new plugin that was developed in partnership with Joe Duplantier of Gojira. If you want to test the state of the art, NeuralDSP offers limited free trials of their products.
If you'd like to test some open source pre-trained models or train your own models for use in a real-time plugin, the GuitarML project from Keith Bloemer brings together the efforts of many into a single place. The SmartGuitarPedal repo has pre-trained overdrive pedals and SmartGuitarAmp has multi-channel tube amp clones. All of these models are WaveNet based and integrate with any Digital Audio Workstation in the form of a standard VST plugin.
Conclusion
Looking forward, I think we can safely say that Machine Learning will become a standard tool in the toolbox of digital amp modeling. Deep Learning in particular is almost perfectly suited for the challenge of jointly optimizing an end-to-end non-linear system on unstructured data. The traditional approaches achieve effective results, but are labor intensive and ripe for disruption. They also have limitations that ML approaches do not, like the inability to elegantly model the interactions of knobs on the amp.
There are still challenges that remain for ML-based solutions in this space. The first is just the engineering to get these models to run in real-time on the hardware that's available. This hurdle should only get smaller with time as software tools are built for making it easier to translate models to embedded systems and hardware innovations continue.
The second type of challenge is in learning “the art of ML” in this domain. Problem domains like computer vision and NLP evolved a “bag of tricks” that, taken together, make big quality differences. In reading these papers, I see some of these nuances like: pre-emphasis filtering that makes the cost function more sensitive to higher frequencies, which humans perceive as louder; or having the LSTM layer predict the residual of output and input by summing a skip connection rather than directly mapping input to output. Some of these will be more important than others and it will take time and information sharing to get broader understanding.
Perhaps most importantly, there's a data availability challenge, as the models can only be as good as the data. The cost of creating a high quality, systematic dataset of an expensive piece of gear is substantial. Entire businesses like Top Jimi Profiles exist to do that, where the hard part is going through the laborious process of setting up excellent sounding guitar signal chains and the easy part is running a tool suite to capture it (Kemper profiling in Top Jimi's case). Once this data is created, there's little incentive to share it. We'll need projects like GuitarML for progress to be made in the larger community rather than being confined within the walls of private institutions.
The bad news is also the great news: for us to make progress in this domain, we just need to fiddle with guitar gear more.
References
-
Eichas, Felix, Stephan Möller, and Udo Zölzer. “Block-oriented gray box modeling of guitar amplifiers.” Proceedings of the International Conference on Digital Audio Effects (DAFx), Edinburgh, UK. 2017.↩
-
Oord, Aaron van den, et al. “Wavenet: A generative model for raw audio.” arXiv preprint arXiv:1609.03499 (2016).↩
-
E. Damskägg, L. Juvela, E. Thuillier and V. Välimäki, “Deep Learning for Tube Amplifier Emulation,” ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, United Kingdom, 2019, pp. 471-475, doi: 10.1109/ICASSP.2019.8682805..↩
-
Wright A, Damskägg E-P, Juvela L, Välimäki V. Real-Time Guitar Amplifier Emulation with Deep Learning. Applied Sciences. 2020; 10(3):766. https://doi.org/10.3390/app10030766↩